|
本章主要想和各人分享下正则表达式的一些根本用法,渴望可以大概对一些小白有所帮助,也为了防止自己以后遗忘相干知识点,下面我们正式进入主题。
一、正则表达式
1、正则表达式是由普通字符(比方字符 a 到 z)以及特别字符(称为元字符)构成的笔墨模式。
2、正则表达式作为一个模板,将某个字符模式与所搜刮的字符串举行匹配。
3、在编写处置惩罚字符串的步调或网页时,常常会有查找或更换符合某些复杂规则的字符串的必要。
4、正则表达式就是纪录文本规则的代码。
作用:
1、查找数据
2、更换数据
正则表达式能做什么(字符串的匹配、字符串的提取、字符串的更换)
二、正则表达式的构成
1、普通字符(如果直接写多个普通字符,则会被当做一个团体的字符串来匹配)
这包罗全部的巨细写字母字符,全部数字,全部标点符号以及一些特别符号。
比方:Hello world xyh666
2、界说字符集(取值范围)(该点都是匹配单个字符,要想匹配字符串必要联合限定符来实现)
[a-e] 表现a到e这些字符中的某一个字符
[aeiou] 表现aeiou这5个字符此中的某一个字符
[a-zA-Z] 表现大写、小写字母中的某一个字符
[0-9] 表现0到9之间某一个数字
^ 代表非
[^lsjd] :不是中括号中的任意一个字符
[^a-f] :a-f范围外的任意一个字符
3、组合字符(大写表现非)(该点都是匹配单个字符,要想匹配字符串必要联合限定符来实现)
\d :匹配一个数字字符。等价于[0-9]。
\D :匹配一个非数字字符。等价于[^0-9]。
\w :匹配一个字母或一个数字或一个下划线或一个汉字。
\W :匹配一个非字母、非数字、非下划线和非汉字的字符。
\s :匹配一个任意的空缺符,包罗空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
\S :匹配任意一个非空缺符。等价于[^ \f\n\r\t\v]。
\b :匹配单词的开始或竣事的位置。
\B :匹配不是单词开头或竣事的位置。
4、特别字符
$ :表现字符串的末了位置(以什么末了)
^ :表现字符串的开始位置(以什么开始)(在取值范围中还表现非)
. :一个点表现匹配一个除换行符 \n之外的任何单字符(匹配单个字符,要想匹配字符串必要联合限定符来实现)
| :大概的意思,指明两项之间的一个选择 与[...]雷同
\ :这个符号是用来转义的
( ) :分组,标志一个子表达式的开始和竣事位置
5、常用限定符
=================匹配次数=================
{m} :其前一单元严酷出现m次(重复m次)
{m,} :其前一单元出现至少m次(重复m次或更多次)
{m,n} :其前一单元出现至少m次,最多n次(重复m到n次)
=======================================
=================多次匹配=================
* :其前面谁人单元出现0次或任意次数(重复零次或更多次)
+ : 其前面谁人单元出现1次或1次以上 至少匹配一次(重复一次或更多次)
? : 其前面谁人单元出现0次或1次(重复零次或一次)懒惰匹配(尽大概短匹配)
=======================================
6、贪婪与懒惰(贪婪模式和非贪婪模式)(尽大概长匹配和尽大概短匹配)
*? 重复任意次,但尽大概少重复
+? 重复1次或更多次,但尽大概少重复
?? 重复0次或1次,但尽大概少重复
{n,m}? 重复n到m次,但尽大概少重复
{n,}? 重复n次以上,但尽大概少重复
7、分组
当用()界说了一个正则表达式组后,正则引擎则会把被匹配的组按照次序编号,存入缓存。
默认环境下,每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。
我们可以通过“\数字”的方式举行引用已经存入缓存的组。\1引用第一个匹配的组,\2引用第二个组,以此类推。
括号内的内容会被当成一个团体举行匹配。
8、非获取匹配和预查(零宽断言)
非获取匹配:是指正则引擎不会把被匹配的组存入缓存,我们也无法通过“\数字”的方式举行引用我们的组。
预查:预查不斲丧字符,也就是说,在一个匹配发生后,在末了一次匹配之后立即开始下一次匹配的搜刮,而不是从包罗预查的字符之后开始。(即用来预查的表达式字符串不会被斲丧,它只是用于指定一个位置)
零宽断言:用于查找在某些内容(但并不包罗这些内容)之前或之后的东西,也就是说它们像\b,^,$那样用于指定一个位置,这个位置应该满意肯定的条件(即断言),因此它们也被称为零宽断言。
===========================================================================================
(?=exp)也叫零宽度正预测先行断言,它断言自身出现的位置的反面能匹配表达式exp。好比\b\w+(?=ing\b),匹配以ing末了的单词的前面部门(除了ing以外的部门),如查找I'm singing while you're dancing.时,它会匹配sing和danc。
(?<=exp)也叫零宽度正回顾后发断言,它断言自身出现的位置的前面能匹配表达式exp。好比(?<=\bre)\w+\b会匹配以re开头的单词的后半部门(除了re以外的部门),比方在查找reading a book时,它匹配ading。
===========================================================================================
(?:pattern) 非获取匹配,匹配pattern但不获取匹配结果,不举行存储供以后利用。这在利用或字符“(|)”来组合一个模式的各个部门时很有效。比方“industr(?:y|ies)”就是一个比“industry|industries”更大抵的表达式。
(?=pattern) 非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不必要获取供以后利用。比方,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不斲丧字符,也就是说,在一个匹配发生后,在末了一次匹配之后立即开始下一次匹配的搜刮,而不是从包罗预查的字符之后开始。
(?!pattern) 非获取匹配,正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串,该匹配不必要获取供以后利用。比方“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。
(?<=pattern) 非获取匹配,反向肯定预查,与正向肯定预查雷同,只是方向相反。比方,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。
(?
三、C#代码调用正则表达式
- 定名空间 System.Text.RegularExpressions
-
- 1、new Regex(正则表达式).IsMatch(要匹配的字符串) 返回bool
- 2、Regex.Match
- Match match = Regex.Match("age=30", @"^(.+)=(.+)$");
- if (match.Success)
- {
- Console.WriteLine(match.Groups[0].Value);//第0组 输出完备的字符串 age=30
- Console.WriteLine(match.Groups[1].Value);//第1组 age
- Console.WriteLine(match.Groups[2].Value);//第2组 30
- }
- 3、Regex.Matches
- StringBuilder sb = new StringBuilder();
- sb.Append("<Name>张三</Name>\r\n<Name>李四</Name>\r\n<Name>王五</Name>");
- MatchCollection mc = Regex.Matches(sb.ToString(), @"(?<=<Name>).*(?=</Name>)");
- foreach (Match m in mc)
- {
- Console.WriteLine(m.Value);
- }
四、示例阐明
接下来针对第二大点的内容我们举些例子来阐明:
示例1(普通字符):
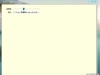
我们用 xyh 来匹配 xyh123 如下图所示:
从上面的正则表达式测试器匹配的结果可以看出:如果直接写多个普通字符,则会被当做一个团体的字符串来匹配。
示例2(元字符和限定符):
我们用 \d 来匹配 xyh123 如下图所示:
从匹配的结果可以发现\d只是匹配单个数字,以是有三个结果,分别为1、2、3,那如果想匹配一整个字符串123要怎么办呢?此时就要联合限定符来实现了。继续来看下下面的一张图。
从图中可以看出联合限定符后就可以实现匹配到123这个字符串了。
示例3(普通字符和元字符组合):
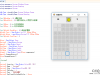
我们用 https://www\..+\.com 来匹配这么一句话:https://www.jd.com两个链接https://www.taobao.com 如下图所示:
可以发现匹配的结果为完备的一整句话,那为什么不是匹配出2个结果分别为 https://www.jd.com 和 https://www.taobao.com 呢?
那是由于默认环境下正则表达式接纳贪婪模式匹配(即尽大概多匹配),以是匹配出了完备的一句话,此时可以用?来实现非贪婪模式匹配(即尽大概少匹配),如下图所示:
如许就匹配出了2个结果
示例4(分组):
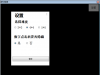
我们用 (abc)\1 来匹配 abcabc666 如下图所示:
从图中可以看出匹配结果为abcabc,为什么会是如许呢?起首我们分组(abc)匹配到存入缓存中的值为abc,通过\1的方式就取到了存入缓存中的第1个分组值abc,这个分组值abc与原来分组(abc)匹配到的字符串abc构成新的匹配字符串abcabc,用新的匹配字符串abcabc去匹配abcabc666得到的匹配结果就是abcabc了。
示例5(非获取匹配):
非获取匹配(?:pattern)如下图所示:
从图中可以看出非获取匹配,匹配pattern但不获取匹配结果,不举行存储供以后利用。因此无法通过“\数字”的方式来获取。
示例6(预查和零宽断言):
预查不斲丧字符,它只是用于指定一个位置,如下图所示:
从图中可以看出用 ab(?=a) 来匹配 ababa123 时会得到两个结果而不是一个结果,那是由于预查不斲丧字符(即不会斲丧用来预查用的表达式exp对应的字符),它只是用于指定一个位置,以是在第3个位置的a(即第2个a)没有被斲丧掉。当匹配到第1个结果ab后会从第3个位置的a(即第2个a)开始查找下一个能匹配的字符串,而不是从第4个位置的b(即第2个b)开始查找,这就表明了为什么会匹配到2个结果了。
PS:本文仅是个人看法 ,如有表述错误接待批评指正!
正则表达式测试器:
- 链接:https://pan.baidu.com/s/1CwyrLH2dwbBk1KVi2FCGDw
- 提取码:nwyc
版权声明:本文部门形貌摘自网络,如有雷同纯属偶合,如有侵权请及时接洽本人修改,谢谢!!! | 











 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡